-David deBoisblanc, April 7, 2021

Having been heavily involved in microservices over the past 9 years, at multiple clients and across many projects, I have watched the entire ecosystem evolve. What was on IT thought leadership’s mind about the subject has changed in just the last year and a half.
The bewildering array of cloud options, development paradigms, toolsets and open source offerings is converging with the trend towards distributed microservices architecture. This has opened the door to performance possibilities and system maintainability.
Increasingly the challenge of performance optimization has been centered on service to service communication, which has emerged as the critical path for many implementations. Simply put the network is a very key constraint. This challenge has sharpened focus on containerization, orchestration and proxies/ gateways (for ex. Docker, Kubernetes and Envoy).
The simplified view of the not so simple set of the challenges are:
- Routing (service to service communication)
- Security and Reliability of communications
- Observability
Enter the service mesh which manages service to service communication.
Service Mesh: What and Why
The key attributes of the service mesh are:
- Routing:
Traffic needs to be routed and controlled while also being extremely resilient.
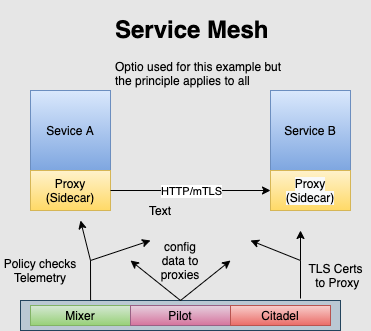
Proxies (sidecar) deployed against each service seamlessly routing all traffic. These proxies are operating and are aware at Layer 7 in the stack. The result is that routing decisions and metric classification can utilize application layer metadata such as HTTP headers. This presents tremendous opportunity with service mesh configuration to optimize communications and to observe those patterns.
Service mesh provides dynamic service discovery and traffic management. From a DevOps perspective; testing, canary release and incremental rollout are simplified and reliable through traffic shadowing and splitting.
- Security and Reliability:
Through the service mesh, “cross cutting” functions such as security standards and reliability requirements can be systematically designed and enforced. Things like ensuring root certificate, access control lists (ACLs) and mTLS can be managed. Also, circuit breakers, retries and rate limiting are all managed by the control plane of the service mesh.
- Observability:
In a distributed microservices environment a service makes a request to another service but because you don’t know which replica will actually take that request there is an observability problem. Of course, this is an exponential problem because of the complexity of traffic. This makes diagnosis of problems and predictable avoidance of problems a great challenge.
Because the service mesh is managing all traffic it can also observe the distributed tracing of a request, error codes and latency. Whether in production or in development of new services this is invaluable in system stability and for remediation. In fact, this feature alone has driven the decision to deploy service mesh at some enterprises.
Network Abstraction
At a higher level, network abstraction is achieved. In a microservices architecture we most frequently find the operation code and the business logic coupled within each respective logical microservice. The consequence of this is any small change to the operation layer, like a security setting, results in a need to redeploy that application.

A service mesh decouples the operation code from the business logic. This enables the ability to change operation code without impacting the business logic and change the operation code with more frequency and much more simplicity.
The higher level abstraction and human-focused control planes gives capabilities into the hands of both the global and the technical architects.
High Level View
A service mesh has two basic conceptual components the data plane and the control plane.
The data plane does the heavy lifting. It handles packets/request, service discovery, routing, load balancing, health checking, authentication and observing.
The control plane is the “brains” and creates a distributed system from the sidecars.
As mentioned earlier, there is a decoupling of operational code from business logic as the proxies under the direction of the control plane are handling the operational requirements.
Also as mentioned, there are differences in where and how the proxies are deployed by the various providers. However, the conceptual architecture is the same. Very typically service mesh is deployed in conjunction with Envoy.
The communication pattern focus is “east-west” remote procedure calls that are service to service. This as opposed to an API gateway which handles “north-south” traffic that travels into the network.
This is important distinction as I have been asked about the need for a service mesh if an API gateway is deployed. They serve different purposes. An API gateway provides traffic control for the ingress, or the outside traffic into the network. Basically, coordinating API and related services. This is the north-south axis.
The east west axis of a service mesh is concerned with sibling traffic between services. As mentioned earlier controlling and optimizing that routing, standardization and observability.
Adoption and Risk Considerations
Service meshes are increasingly becoming part of the landscape in the cloud native application platforms. While it brings plenty of capability to solve problems arising in the microservices environment, as in most things IT, a service mesh is not a magic bullet free from risks.
Considerations:
Some potential issues to consider are the following:
Operational cost: There is an operational cost to deploying and operating a service mesh. Deployment time, adoption by the production team, an additional layer in the microservices environment. There may also be a CPU impact though it is typically very minimal. Even though it introduces 2 new “hops”, these typically happen over the localhost or loopback network interface with minimal latency. However, testing should be performed first to ensure acceptable performance as a risk reduction step prior to moving forward.
Traffic management layer conflict: The possibility of layer conflicts with issues like retries having policy control from the service mesh control panel and also being handled within the code of the application. Serious conflicts can arise like duplicated transactions.
Multiple Service Meshes: Through acquisitions and multiple business segments several disparate service meshes may be deployed. This presents a consolidation challenge as several control layers are present and there are some differences in the architecture of the various service mesh options. For example, Optio and Linkerd have a very different paradigms on where to deploy the “sidecar” proxies. The APIs are different, and the configuration parameters can be conflicting.
“Enterprise Service Bus” pitfalls: You may have recognized the similarity between a service mesh concept and the ESBs of the SOA era. And there are some lessons to be learned from the SOA mistakes. For example, the tight coupling of business logic into the communication bus. And the lack of interoperability between disparate ESBs (see above). However, there are design decisions that greatly mitigate this risk and the previous one.
Incorrectly planned deployment: Big Bang vs. iterated rollout. Both have their pros and cons though the iterated rollout usually has less risk. But even the iterated rollout needs to be carefully planned and then a consistency of vision needs to be extended across a longer period.
This list of antipatterns is not exhaustive but they top the lists of the issues that we and others have seen.
Deployment Considerations
In deployment, careful planning around several topics is critical
Incremental and iterated rollout is almost always the best option but there can be use cases for big bang. Nevertheless, incremental rollout also requires careful planning. I am probably stating the obvious though I have seen cases where the team just started with no real plan and generally had to retreat and start over.
We have been deploying with an ‘abstract the abstraction’ step where we utilize tools and architecture to simplify the control panel deployment and allow for flexibility in regard to disparate service meshes and ease the adoption of the support team that will manage the system in production.
A careful understanding of deployed processes like retries, etc. to make sure that duplicate and conflicting policies and procedures do not plague the system
Service Mesh Providers:
As mentioned before there are several popular options being deployed today.
Providers of service mesh tools and frameworks:
| Istio | Kuma |
| Linkerd | AWS App Mesh |
| Maesh | Consul |
There is plenty of buzz surrounding the subject of service mesh and with good reason. As a concept it is increasingly being embraced and deployed.
As always if you have any questions, please contact me and I will be happy to help.
David Duczer deBoisblanc is the managing partner at Duczer East. David has 25 year history in the software and systems engineering domain.
Pingback: Should you consider a Service Mesh | David deBoisblanc's Wordpress Blog
Pingback: Importance of “And” in Microservices – Fuego Tigre